A Chat-Based Job-Matching Agent
I was the technical lead on this project — the final project for the Introduction to AI Agents course at Data Sanity. I designed the end-to-end architecture, set the overall direction, and filled in the gaps across the stack as the team built it out. The code is on GitHub.
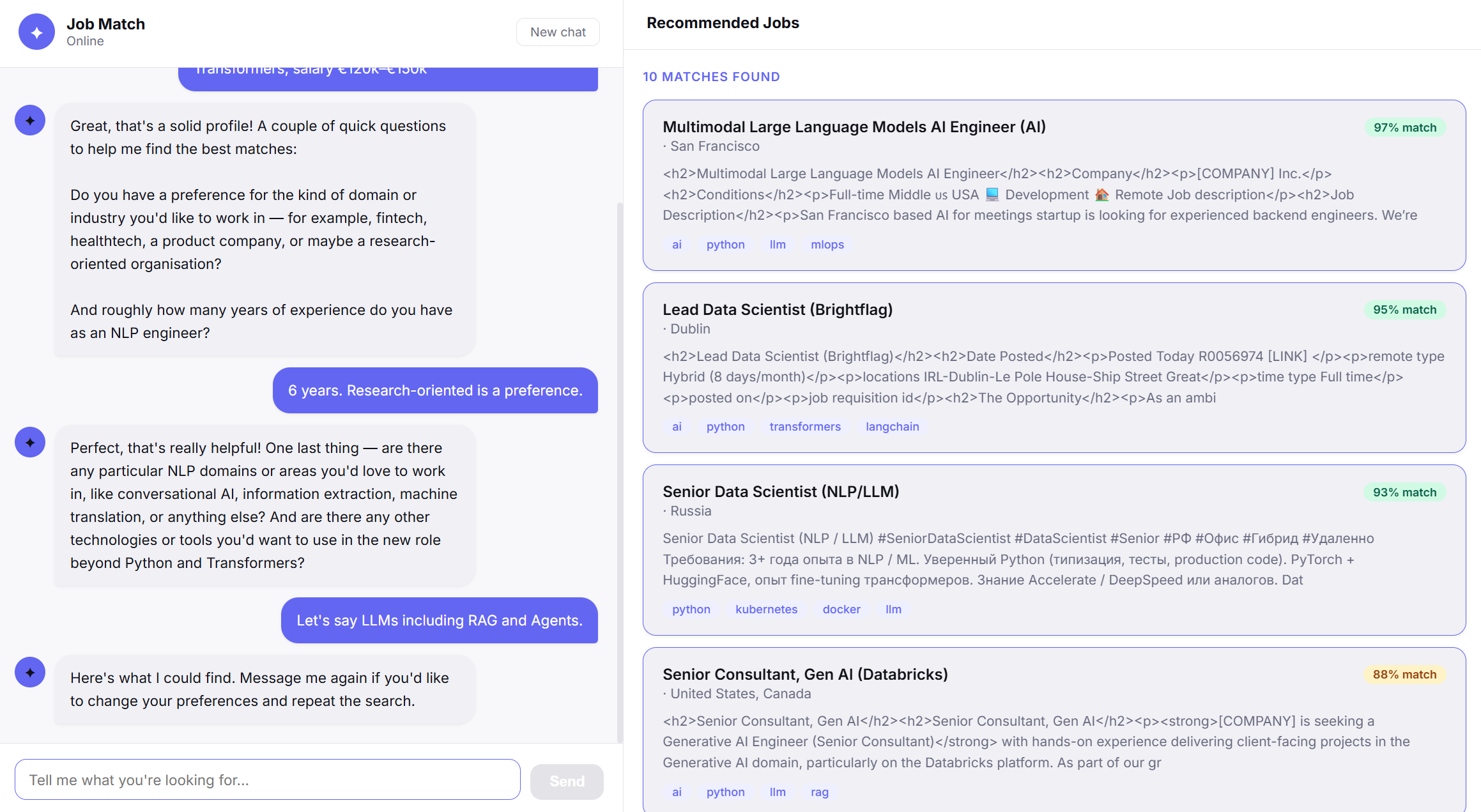
The core idea: free text carries more signal than checkboxes. Intent like “a senior backend role, remote, fintech, that lets me keep Go but pick up Rust” doesn’t fit any dropdown. The agent collects that intent through chat, structures it, and retrieves ranked vacancies — all in the same conversation thread.
Stages
The pipeline has four stages:
1. Conversational profiling. A fast streaming LLM asks one or two questions at a time to build a candidate profile — never a form. Once enough context is collected, it triggers the search.
2. Schema extraction. A more capable model parses the full conversation into a validated Pydantic schema capturing skills, preferred positions, tech stack, location, salary, work mode, and exclusions. Using two distinct LLM tiers keeps latency low without sacrificing extraction accuracy.
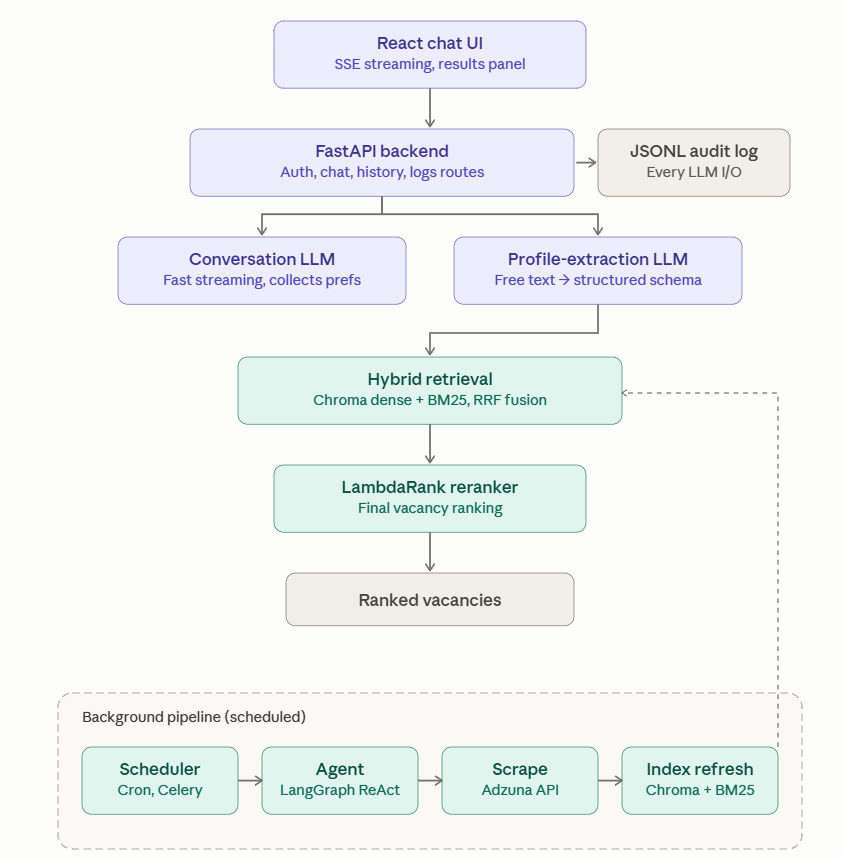
3. Hybrid retrieval. A Chroma dense index and an in-memory BM25 index run in parallel over the same vacancy corpus. Their ranked lists are fused via reciprocal-rank-fusion (RRF) — a rank-based approach that handles different score scales cleanly.
| Retrieval | Recall@20 |
|---|---|
| Dense only | 67.1% |
| Hybrid (RRF) | 75.4% |
4. LambdaRank reranker. A LightGBM model reorders the top 20 results using retriever scores alongside 82 schema-derived tabular features: skill overlap, location compatibility, seniority match, salary band, and more. Feature ablations show that structured schema features carry most of the gain — a separate LLM-as-expert grader was tried but added little on top and was removed from the production path.
| Reranker | Recall@1 | NDCG@10 |
|---|---|---|
| Cosine baseline | 55.2% | 0.721 |
| LambdaRank | 85.9% | 0.936 |
A background LangGraph ReAct agent keeps the index fresh by scraping Adzuna on a schedule, broadening its queries when results are thin, and hot-merging new listings without restarting the API.
What made this project stand out was the team’s commitment to rigorous evaluation: a wide labeled set of candidates with ground-truth source vacancies, per-stage ablations, and miss-analysis broken down by region and specialization to surface systematic gaps. That discipline is what separated this from a typical course project.
Architecture
The system layers a React chat UI (streaming over SSE) on top of a FastAPI backend, with two distinct LLM roles — a fast model driving live chat, and a more capable one for one-shot schema extraction — and a self-contained ML pipeline for retrieval and reranking. A scheduled LangGraph ReAct agent runs independently in the background, keeping the vacancy index fresh without touching the serving path. All LLM calls go through LiteLLM, making the provider — Claude, Mistral, GitHub Models — swappable without code changes.
Conclusion
Job matching is, at its core, a retrieval and ranking problem — and this project treats it as one. The conversational layer removes friction from the user side; hybrid retrieval and a learned reranker handle the precision on the system side. What I found most valuable in leading this work was seeing how much a principled evaluation setup shapes the entire development process: once you can measure each stage independently, you stop guessing where to invest effort.