How to Automate Prompt Engineering with OPRO
In the past few years prompt engineering has emerged as a critical technique for optimizing the performance of large language models (LLMs).
For example, CoT with a help of reasoning models (e.g., DeepSeek) in a manual setting has proven to be a default approach to prompt engineering. Since a manual approach can consume a significant amount of engineer’s time, this sets the stage for introducing the Optimization by PROmpting (OPRO) approach.
The OPRO method leverages LLMs as optimizers, with their code being publicly available: google-deepmind/opro. OPRO authors claim that it is feasible to achieve improvements in hard prompts for various tasks, including BIG Bench Hard which is a diverse evaluation suites. That makes OPRO appealing to try for any use case that requires a manual prompt engineering.
Here is the diagram that represents how OPRO is operating throughout training:
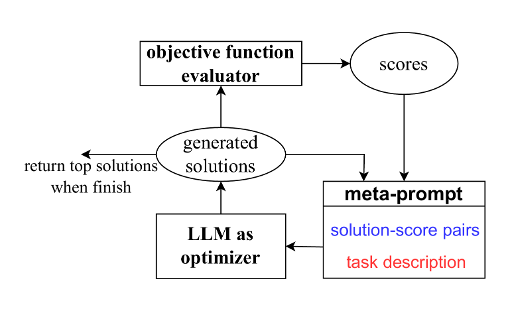
In order to specify OPRO for one’s task, it is required to define the following parts:
- Training corpora. Task-specific data. For example, for text generation problems such as machine translation, summarization or paraphrasing, it is a set of aligned pairs between sources and references.
- Meta-prompt. This is what the optimizer gets as an input to make an optimization step. There is a thorough explanation of the meta-prompt design in the original paper.
- Optimization objective. Should be handcrafted carefully. The easiest case is when it is possible to stick to accuracy. More complicated use cases involve the addition of LLM-as-a-judge approaches.
- LLM API access. Since LLM as an optimizer is a central concept of OPRO, the user should have an API access and should be ready to spend dozens of thousands of processed tokens per training run.
Finally, I can recommend to use OPRO when a user:
- Either optimizes the prompt of the Large Language Model which is capable of generating diverse outputs and can show large optimization objective scores.
- Or is not expecting the prompt to which OPRO converged to as a final version.
In my use case, the optimization objective tended to fluctuate around some threshold throughout several training launches.